

















Distributed web3 cloud for running apps
Build and deploy scalable applications on Flux, a global, decentralized cloud computing network, enabling flexible, censorship-resistant development.
What is decentralized cloud computing?


Decentralized cloud computing spreads resources like RAM & storage across a network of devices operated by individual users, rather than a centralized giants like AWS.


How does Flux work?
Flux is powered by thousands of globally distributed, user-operated nodes, which makes the network redundant with zero points of failure.
Why decentralized cloud?
- Instant Data Transfer
- Fault Tolerant-Resilience
- Automatic Failover
- Complete Data Sovereignty

How does Flux support devs?
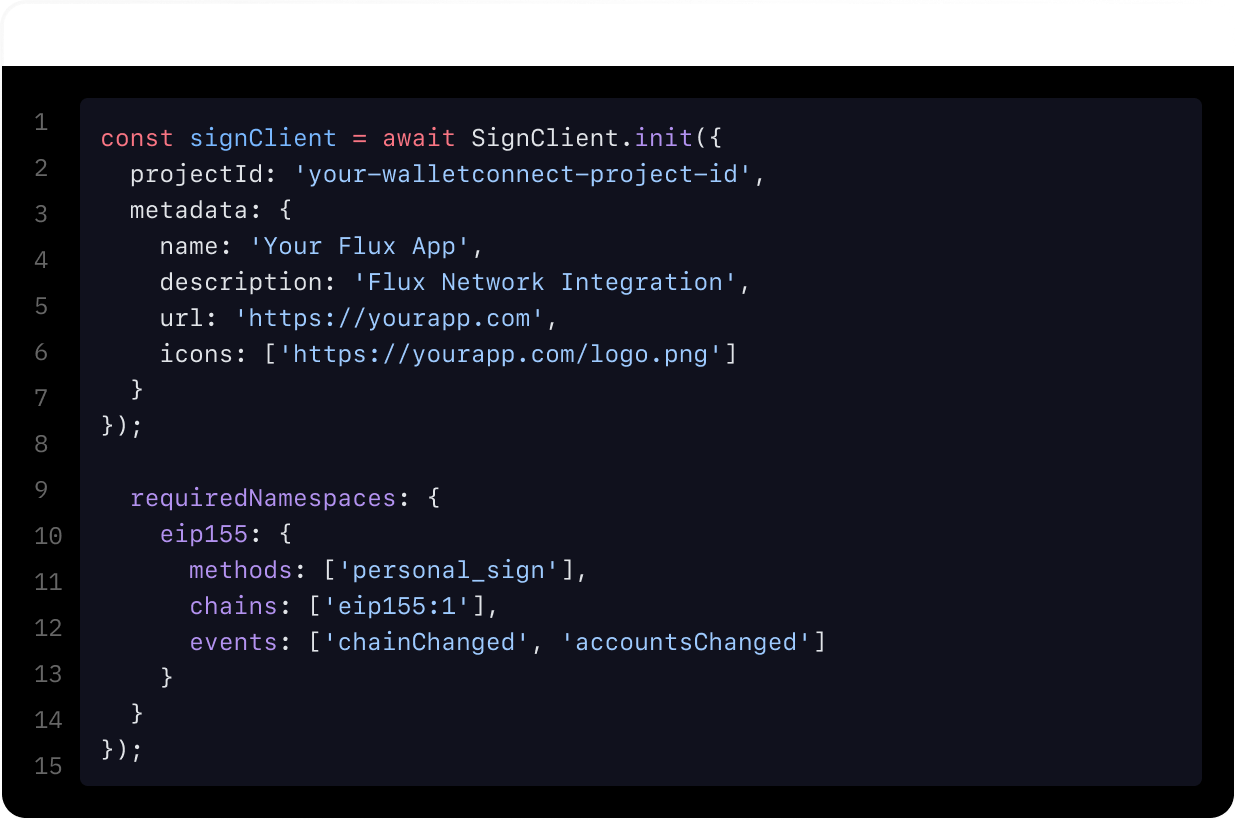
Extensive Docs
With in-depth setup guides for every product in our stack, Flux Docs grants a smooth developer experience from data provision to app deployment.
Unlimited Scalability
Open participation + Globally distributed hardware with top of the line GPUs = unlimited, elastically scalable compute for censorship-free development.


Flux Foundation
The Foundation is a community-governed growth funnel for Flux that receives a fixed portion of block rewards as a consistent revenue stream to fund network growth through yield-generating infrastructure.

What makes Flux great for developers?
Distributed Hardware
Independent hardware providers mean localized and low-latency app development.
Interoperability
Flux supports Docker containers and deployments directly from Git repos.
Secure Infrastructure
Docker Hub, IPFS, 24/7 state monitoring, and pre-allocated disk space on provider hardware.
Needs hands-on support?
Experience fully-managed services with 24/7 developer support from InFlux Technologies. Scale your org from a small business, to a booming enterprise.

