


















TL;DR: The circular funding between hyperscaler cloud providers like AWS and Google Cloud Platform, GPU manufacturers like NVIDIA, and AI development companies like OpenAI is forming compute cartels that aim to control compute infrastructure and chip production for greater AI inference.
Who: This article is for Akash and Flux community members wondering how decentralized cloud networks can combat the formation of compute cartels.
What To Do: Pilot one workload on a decentralized compute marketplace like FluxEdge or Akash to see how efficient and resilient these networks are compared to hyperscaler infrastructure.
Next Steps: Turn your pilot into a migration playbook using the article’s vendor-lock-in and DePIN sections so that you can move your setup away from compute cartel infrastructure.
_____________________________________________________________________________
Introduction
A cartel is a predatory oligopoly in which a small group of firms with similar interests collude to control market share in an industry. Firm operations are coordinated between cartel members to maximize joint profits, influence industry trends, and generally shape market growth according to the cartel’s vision.
In 2025, when AI development and fast data transmission are the biggest priorities of tech, computational energy (compute) provision is the name of the game. Compute is an umbrella term referencing the resources, such as processing power, bandwidth, memory, and storage, that power AI systems, web applications, and other computing workloads.
Compute is provided by microchip hardware that uses various processing units, such as CPUs and GPUs, to perform calculations, process data, and execute programmed instructions. These processing units are housed in servers and data centers that act as nexus points in global telecommunications networks through which data and internet traffic flow.
Massive cloud firms, such as AWS, chip manufacturers like NVIDIA, and AI development firms such as Palantir and OpenAI, are beginning to consolidate computing resources amongst themselves, forming “compute cartels” that control the manufacturing of microchips and computing infrastructure, and influence funding streams, pricing structures, government legislation, and consumer habits.
Compute cartels are primarily forming through hyperscaler cloud infrastructure operated by centralized authorities that engage in predatory vendor lock-in. Additionally, compute cartels are forming through circular funding within the AI development landscape, which generates artificial demand for compute services, creating the illusion of an “AI bubble” and reinforcing dependencies on a small number of compute providers.
For the past several years, a countermovement has been on the rise: Decentralized Physical Infrastructure Networks (DePIN). DePIN represents a structural alternative to centralized compute cartels, in which control and ownership of compute infrastructure are distributed among many individual network participants rather than centralized within an oligopoly. DePIN moves compute away from cartels and toward open, permissionless, and user-driven markets.
By enabling individuals and organizations to contribute underutilized computing resources to a shared network, DePIN creates competitive pressure that breaks vendor lock-in, eliminates egress fees, and dismantles the circular funding loops that prop up artificial demand.
Akash Network and Flux are at the forefront of this DePIN disruption. Akash operates a decentralized cloud marketplace where anyone can lease GPU and CPU resources from a global network of independent providers, offering higher cost savings than hyperscalers like AWS.
Flux comprises a global, decentralized cloud architecture in which compute provisioning is handled across thousands of physically distributed computational nodes to eliminate single points of failure, boost uptime, and improve edge capabilities for redundant, containerized workloads.
Hyperscaler Cloud Infrastructure and the Vendor Lock-In Trap
Hyperscaler cloud infrastructure refers to the massive, centralized data centers operated by a handful of dominant providers like AWS, Microsoft Azure, and Google Cloud. These facilities house thousands of servers packed with GPUs, CPUs, and storage systems that deliver computing power to enterprises and developers worldwide.
Hyperscalers achieve economies of scale by consolidating resources in enormous facilities, allowing them to offer competitive pricing and vast capacity that smaller providers struggle to match.
An economy of scale is when a firm increases efficiency by scaling the production of a single product. A firm will specialize in bulk manufacturing a single product because producing many units in tandem reduces the average unit production cost.
However, hyperscalers achieving economies of scale in compute provisioning mean a concentration of power that creates a web of dependencies between hyperscalers and their customers.
The Hyperscaler Supply Chain: A Web of Dependencies
The hyperscaler supply chain is a complex, vertically integrated network that begins with chip manufacturers and ends with end-user applications. At the foundation are semiconductor fabricators such as TSMC and Samsung, which manufacture the processing units that power data centers. These chips are then sold to hardware providers such as NVIDIA, AMD, and Intel, which design and distribute GPUs and CPUs.
From there, hyperscalers like AWS, Azure, and Google Cloud purchase these processing units in massive volumes and integrate them into server configurations housed in their data centers. These facilities are connected to global telecommunications networks, enabling data transmission and internet traffic to flow through centralized nodes controlled by a small number of providers.
Software and middleware layers sit on top of this hardware infrastructure. Cloud providers develop proprietary management systems, orchestration tools, and APIs that allow customers to access compute resources. This creates dependencies not just on hardware, but on the entire software ecosystem built around it.
Finally, enterprises and AI developers consume these resources by renting compute from hyperscalers to train models, run inference, host applications, and store data. Every layer of this supply chain consolidates power upward, channeling control into the hands of a few dominant players who influence pricing, access, and innovation across the entire stack.
The Hidden Costs of Hyperscaler Infrastructure
Hyperscaler data centers place immense strain on local energy grids, often consuming as much electricity as entire cities. Their operations generate mountains of electronic waste as processing units are replaced preemptively before the end of their lifecycle to make room for newer GPU models that can run AI workloads slightly faster.
Freshwater consumption by hyperscaler datacenters is also incredibly unsustainable, with individual facilities consuming millions of gallons daily to cool servers and prevent overheating. In water-stressed regions, this demand competes directly with residential and agricultural needs, creating resource conflicts that hyperscalers rarely address in their sustainability reports or pricing models.

Operating costs remain high despite economies of scale. The capital required to build and maintain these hyperscaler data centers creates barriers to entry that prevent meaningful competition.
Furthermore, because these data centers concentrate computing resources in fixed locations, they suffer from inherent single points of failure: even a brief outage at one facility can cascade into a global network outage, resulting in billions of dollars in lost revenue from service disruptions. Centralized hyperscaler infrastructure is fragile.
Vendor Lock-In: The Strategic Weapon of Hyperscalers
The real danger of hyperscaler dominance isn’t just operational. It’s strategic.
Centralized cloud providers engage in aggressive vendor lock-in tactics designed to make it prohibitively expensive and technically challenging for customers to move to a different cloud vendor. This lock-in operates on two levels: data migration constraints and egress fees.
Data migration constraints stem from proprietary architectures. Hyperscalers build ecosystems with custom APIs, specialized services, and unique configurations that deeply integrate with customer applications.
Moving workloads to another provider after the integration is established requires extensive reconfiguration, testing, and potential rewrites of core systems. For companies running mission-critical AI operations, the risk and resource investment of migration often outweigh the potential savings from switching to a cheaper vendor.
Egress fees amplify this trap. While hyperscalers charge little or nothing to upload data to their platforms, extracting or egressing it incurs massive costs. Companies that store terabytes or petabytes of training data, model weights, or user information face egress fees that can reach hundreds of thousands or even millions of dollars. This pricing structure creates a financial moat around customer data, discouraging any attempt to diversify compute sources or migrate to competitor cloud environments.
The result is captivity. Customers become economically and technically bound to their hyperscaler, unable to negotiate from a position of leverage. Pricing increases, service degradation, or unfavorable terms become difficult to resist because the cost of exit exceeds the cost of compliance.
This dynamic transforms hyperscalers from service providers into gatekeepers. They don’t just sell compute. They control access to the infrastructure that powers AI development, web applications, and enterprise operations. And as AI workloads grow more intensive, this control only tightens.
Vendor lock-in and hyperscaler dominance lay the foundation for the formation of compute cartels. When customers can’t leave, providers can coordinate pricing, restrict hardware access, and shape market conditions without fear of competitive pressure. The stage is set for collusion, not competition.
Circular Funding Explained
Another way modern-day compute cartels are forming is through circular funding. Circular funding/financing, not to be confused with circular trading, is an aggressive vertical-integration tactic in which companies invest in their own customers to accelerate growth. Vertical integration is a form of market control where a company seeks to consolidate and buy out its own supply chain.
Suppose a company controls its own means of production, distribution, and consumption, rather than relying on third-party intermediaries. In that case, it drastically reduces its operating costs throughout the supply chain.
So, circular funding is a method of orchestrating deal flows between a firm’s customers and itself to prop up business. However, a firm’s customers aren’t everyday consumers; they’re other large firms that purchase enterprise goods and services at scale within the same supply chain.
Circular funding keeps money moving within isolated circles where market activities are influenced by several colluding firms that have vertically integrated to control market share. By consolidating competing firm operations, cartels can coordinate funding in vacuums where demand is faked, propping up business through continuous reinvestment.
Rather than demand-fueled growth that generates actual profits for a company, circular funding fuels growth artificially with recycled value. It doesn’t create compounding revenues; it just supports enough deal flow to keep the lights on at the end of the day.
Circular funding is subsidized growth that distorts valuations, as output remains high for firms while their profits stagnate from a lack of actual business; low margins are acceptable because productive volume appears high.
Circular Funding in AI Development
Now, circular funding is the leading proponent of AI development; it is driving 2025’s crazed demand for adoption and enabling massive infrastructure establishment to scale model training and parameters.
Executing AI workloads means rapidly performing complex computations, which requires powerful processing units. To run these processing units, computing resources are required. As AI workloads scale, more processing units are needed, each demanding increasingly intensive compute.
So, a cyclical pattern begins to form: infrastructure and hardware providers invest in AI builders; AI builders use that investment to purchase compute from hyperscalers to power their development. To scale that development, hyperscalers then purchase additional processing units from infrastructure and hardware providers, who then invest more into AI builders to scale development even further.
Companies Involved
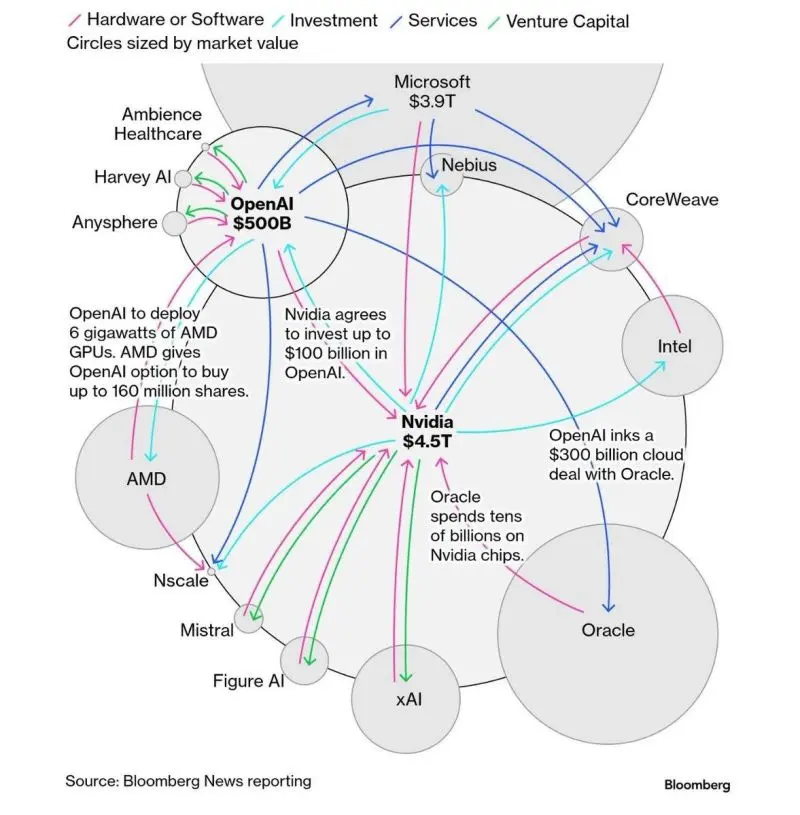
There are three firms at the center of the AI landscape perpetuating the potentially devastating cycle of circular funding: Nvidia (hardware provider), OpenAI (AI builder), and Oracle (hyperscaler).
Nvidia has invested $100 billion into OpenAI to fund research and development. To power that development, OpenAI has arranged an exclusive $300 billion deal with cloud provider Oracle to purchase computing resources from Oracle’s data centers.
For AI workloads to scale, Oracle’s datacenter infrastructure needs to expand with additional processing units to provide more compute. To accomplish this, Oracle goes right back to Nvidia, purchasing tens of billions of dollars’ worth of new processing units to integrate into new data centers. Nvidia then starts the cycle all over again with a fresh investment round into OpenAI.
Circular Funding and The AI Bubble Illusion
A bubble in a financial market is a circumstance where value is inflated, with nothing actually grounding it, an asset or entity that is essentially all bark and no bite. AI is currently perceived as a bubble because global AI development firms, especially OpenAI, are not profitable but boast unfathomable valuations due to circular funding.
How this Happens
Circular funding creates the illusion of a bubble in the AI landscape, as capital flows among hardware providers, AI builders, and hyperscalers. By purchasing additional processing units from Nvidia to expand datacenters, Oracle is reinvesting in the very companies that rely on them for compute.
Capital returns to the cloud through increased service consumption when OpenAI demands more compute to scale its development, giving the appearance of rapid market growth despite funds simply circulating within an enclosed economic loop.
Scale is achieved through interconnected revenue expectations, not actual deals; explosive growth is suggested but is really fueled by recycled capital rather than by tangible demand. AI builders scale their workloads, hyperscalers accelerate compute provision to signal momentum, and hardware providers ramp up chip manufacturing to justify continuous reinvestment.
The landscape becomes so reliant on circular funding to maintain the illusion of compounding growth that it reinforces its dependence on the very cloud providers that are forming compute cartels and exist at the center of these investment loops.
Because major cloud providers like Oracle invest in greater infrastructure and provide the compute needed to scale AI development, consumers find themselves locked into hyperscaler hardware and pricing models. The more a company grows using subsidized cloud resources from a massive provider, the harder it becomes to migrate workloads elsewhere or diversify its compute sources; the company becomes dependent on hyperscalers.
Such a dependency strengthens the leverage of cloud providers like AWS and Oracle. As this dependency grows, it contributes to the formation of compute cartels, as consumers are locked into pricing, hardware access, and AI development standards controlled by hyperscalers, giving them disproportionate influence over the market.
In effect, circular funding does more than distort growth metrics—it solidifies the structural conditions that allow compute cartels to form and maintain dominance.
By creating artificial momentum and deepening customer dependency, circular funding centralizes control of the AI compute landscape in the hands of a few hyperscalers. The result is a market that appears vibrant and competitive on the surface but is increasingly shaped by closed financial loops, restrictive dependencies, and the concentrated power of major cloud providers.
Disrupting Cartels: What can be done?
As cartels move to consolidate compute, we have to work towards decentralizing the physical infrastructure that powers those resources—separating the ownership and control of hardware from the processing power it provides. DePIN networks achieve this by gamifying compute provision with incentivized participation.
Personal computing devices such as smartphones and laptops can produce much more processing power than is actually used. DePIN harnesses this excess bandwidth, or idle compute, and repurposes it to execute computational workloads across networks. This allows anyone with underutilized hardware to join a DePIN, provide compute, and receive compensation.
Flux and Akash
Two leaders in DePIN, InFlux Technologies (Flux) and Akash Network, offer solutions that directly challenge the formation of compute cartels.
Flux operates a global decentralized cloud network, FluxCloud, and a user-driven peer-to-peer marketplace for distributed computing resources, FluxEdge. The physical infrastructure powering these solutions is geographically distributed to enable low latency and is operated by independent hardware providers to ensure redundancy and resilience.
Akash Network operates the Supercloud, an open and permissionless marketplace for trading diverse compute resources. By aggregating underutilized GPUs from data centers globally, Akash provides a permissionless, cost-effective platform optimized for high-performance tasks like training AI models and deploying containerized applications.
To Close
Idle compute can be scaled dynamically in real time, allowing resources to meet fluctuations in computing demand for intensive AI workloads actively. Leveraging personal hardware with underutilized GPUs is a much more cost-effective way to source compute than through hyperscaler datacenters. Additionally, this method extends the lifespans of processing units, reducing e-waste over time.
Together, Flux and Akash are reshaping the current cloud landscape, challenging predatory and collusive compute cartels through decentralized network control, open governance models, and distributed infrastructure operated by independent compute providers.
These networks avoid single points of failure and feature built-in redundancy and resilience, putting users and developers first. It is time to disrupt compute cartels with decentralization. Check out Flux and Akash today to join the movement and ensure cloud computing remains fair and affordable for all!